
Essay: How many participants is enough for a usability test?
For decades, usability tests have helped to shape products. As the adoption of usability tests increases, the optimum sample size also becomes a point for debate.
A probable reason for its contention could be due to its economics. Varying the number of participants will affect the overall costs (Dumas and Redish, 1999). In addition, to stay ahead of competitors, timelines may be tight. To justify the costs of a larger sample size, the benefits of more sampling needs to be examined and justified. On the other hand, smaller sampling sizes causes problems with accuracy and insufficient coverage of existing problems. Due to the possibility of having outliers, we should generally place less faith in small sample numbers of quantitative research (Kahneman and Tversky, 1971). In non-quantitative aspects of usability tests, the following formula by Lewis (1982) also suggests that bigger sample sizes will increase the coverage of usability problems detected.
Likelihood of problem detection = 1-(1-p)n
In the above formula, p is the probability that problems will occur, and n is the sample size. For example, if 50% of users previously perceived a product to be confusing, p could be taken to be 0.5. If there are two participants in a usability test, then the probability that either one or both subjects will be confused is 0.75. If there are three participants, the probability that at least one will be confused is 0.875. ‘Likelihood of problem detection’ is often taken to also mean the percentage of problems that could be uncovered.
Instead of using the formula to get the sample size n, Virzi (1992) varied n in his experiments, used the Monte Carlo procedure and plotted the graph below.
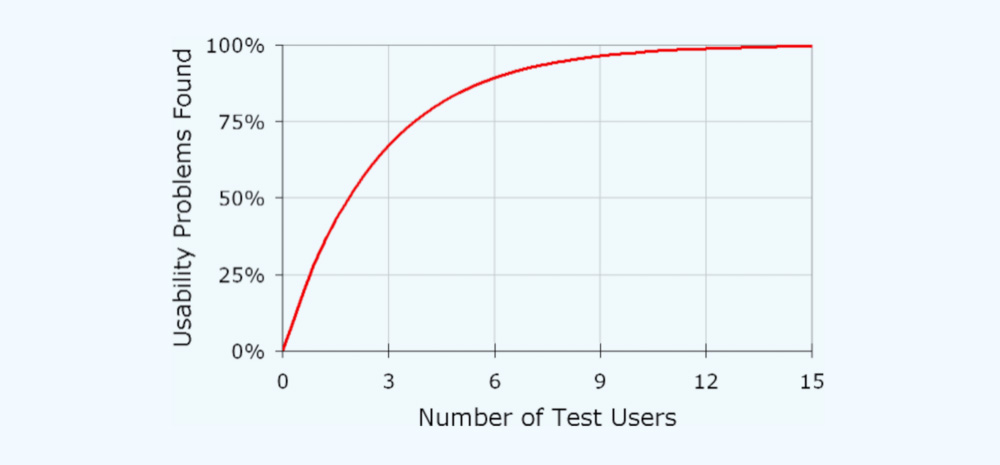
From this graph, it was suggested that four or five participants are enough to discover approximately 80% of the problems. He reasoned that further usability tests with more participants would show repeats of problems and hence provide diminishing returns. Nielsen (2000) also suggested that 5 is enough, considering that iterative cycles of design and testing will cover more problems over time.
Arbitrariness of the variables
However, it might be an unrealistic assumption that there is always pre-existing data for p or that Virzi’s average p is applicable to all tests. In Virzi’s 1992 experiments, he did usability tests on a voice mail system and a calendar system to calculate p. However, the p which applies to the products in Virzi’s experiments may not always apply to the myriad different kinds of products in the world. And even in the same product, there might be different kinds of problems that may occur at different frequencies.
It might also be subjective to say what percentage of problem detection is enough coverage. Although Virzi suggested that severe problems will surface first, Spool & Schroeder (2001) continue to find severe usability issues after the first dozen participants. Would discovering 80% of the total problems be enough, if a major problem lies in the uncovered 20% that would have only been uncovered after the fifth participant?
Moreover, embedded in the idea of problem detection probability is that there is a total number of problems. Molich (2010) suggests that it is otherwise, as there could be an almost infinite number inherent. With ambiguity and arbitrariness, other factors need to be considered.
Factors to consider
1. Type of test and estimation of the frequency
The idea of the summative and formative in usability tests was first introduced in a 1986 HCI conference by Hewett. He explained that the formative is interested to detect and discover problems by gathering user feedback and iterating, while the summative assesses the effectiveness, usability and impact, often focusing on task-level measurements. Often, there may be more iterations in the formative stage where Nielsen’s idea of 5 participants each time over many repeated cycles may apply.
However, the frequency of problem occurring needs to be taken into account. As discussed above, p in the formula may not be always available. Lewis (2006) suggests that this is especially so in formative than summative tests, since the problems are not yet known. In this light, he suggests to estimate p instead. Based on the formula, if it is estimated to affect more than 30% of the users (p = 0.3), 5 participants may be sufficient in a usability test. However, if the estimated frequency is low, for example, if it affects 10%, 21 may be the recommended sample size.
2. Range of specified users and contexts
Usability is also concerned with “the specified users in specified use context”, as seen in its official definition (International Organization for Standardization [ISO], 2018). Caulton (2001) points out that different user profiles will bring up different problems. If the users profiles with the test is numerous or broad, it may be harder to capture a good representation of them in a smaller sample size. For example, in healthcare which typically has a broad range of users, Kaufman et al (2003) studied the use of medical devices in patients’ home and wanted to include users of varying education levels in both the city and in the rural areas. A larger number of 25 in their case was studied to reduce assignment bias.
3. Purpose of the usability tests
It is also important to consider who the findings of the usability test would be intended for. If the goal is to demonstrate the existence of serious usability problems to skeptical stakeholders, then two or three participants, together with the video recordings and anecdotes, may be already sufficient.
4. Speed and Timeline
Mills (1986) describes how her team in Apple performed usability tests and were sometimes given “four to forty-eight hours to make hard decisions about unexpected problems.” Though Mills said that Apple has since improved on its processes, the speed to compete with industry competitors generally is still real in many sectors, perhaps even more so with today’s advancement in information technology. For example, with the Fidget Cube/ Stress Cube, an unnamed guy copied the idea and made a huge profit in a very short time before the original company on Kickstarter could make substantial profits or even patent it. (CNBC, 2017)
Tagged with the idea of speed is also agility and frameworks within the software development industry. For example, Google Ventures developed a system of design sprints which try to compress months of time into a week (Knapp, Kowitz and Zeratsky, 2016). In this format, only one day in the week is dedicated to testing and consolidating the results. Unless the team is huge, the time would be tight and may not allow much time for formal recruitment and extensive detailed planning and execution.
What should we do about it?
Flexibility and Iterations
With the different factors at play as discussed above, we would need to consider the circumstances of each test with flexibility when deciding the number of participants. We cannot discover all the problems anyway. If extensive tests cannot be afforded, it might still be good to pick out the low-hanging fruits and uncover more problems over the next several iterations. It may also be great to maximize the value of each test.
Maximizing Returns with Agility
Generally, in analyzing the Returns on Investment (ROI), the returns of usability tests include the time and manpower saved by the customer and the business when improvements are implemented as a result of the tests (Dumas and Redish 1999).
To test on the right areas that would bring the most improvement, it is essential to recognize the value of each user task and prioritize them. In addition, Racheva et al (2010) suggests that there should be a continuous cycle of re-prioritization, due to ever-changing circumstances. In other words, from a higher-level framework, the iterative processes should be agile so that they will always stay relevant. Among all the backlogs and newer tasks to test, the test design should make sure that the selected tested tasks add value to the customer and business (see How to prioritize in Agile II).
Maximizing ROI by reducing costs
Since cost concerns sometimes intimidate stakeholders to not do any usability tests (Nielsen,1994), Nielsen suggests a “discount usability engineering” where for example, methods like thinking aloud can be simplified. To cut down on usability tests, methods like heuristic evaluation can be used together to supplement.
To reduce costs, instead of independent groups of users for different user tasks, Within-Subjects Designs, where each participant is tested for several tasks, could be also used. Though this may result in learning effects and carry over effects (Greenwald, 1976), counterbalancing measures to mix the orders of tasks around can be employed. Depending on the number of tasks, incomplete counterbalancing may also help reduce the number of participants needed.
Maximizing Returns with good test design
In addition, Molich (2010) also pointed out that if poor methodology is used, the sampling size does not matter. Depending on the purpose, card sorting or tree tests may be more effective than usability tests. Molich also believes that the number of evaluators and their quality also determines the quality of the findings.
Conclusion
When discussing about sample sizes, it’s inevitably a discussion about the balance between “instant results and perfectionism”, as Mills from Apple aptly puts it. To answer the title question of how many is enough, it is hard to give an exact number as it flexibly depends on the various factors discussed. However, if the specified user groups and contexts do not require a large number, if it is combined with multiple iterations, and if extra care is taken to maximize the value of each and every usability test, 5 may be a good compromise, a reasonable, easy-to-remember “discount”.
References
CNBC. This 24-year-old made $345,000 in 2 months. January 2017. Retrieved from https://www.cnbc.com/2017/01/30/a-24-year-old-made-345000-by-beating-kickstarters-to-market.html on 8 October 2019
Dumas, J. S., & Redish, J. (1999). A practical guide to usability testing. Intellect books.
Greenwald, A. G. (1976). Within-subjects designs: To use or not to use?. Psychological Bulletin, 83(2), 314.
Hewett, T. T. (1986). The role of iterative evaluation in designing systems for usability. In People and Computers II: Designing for Usability (pp. 196-214). Cambridge University Press, Cambridge.
How to prioritize in Agile II. Retrieved from https://www.scrumdesk.com/business-value-prioritization-in-scrumdesk/
International Organisation for Standardization. (2018). Ergonomics of Human System Interaction.
Kaufman, D. R., Patel, V. L., Hilliman, C., Morin, P. C., Pevzner, J., Weinstock, R. S., … & Starren, J. (2003). Usability in the real world: assessing medical information technologies in patients’ homes. Journal of biomedical informatics, 36(1-2), 45-60.
Knapp, J., Zeratsky, J., & Kowitz, B. (2016). Sprint: How to solve big problems and test new ideas in just five days. Simon and Schuster.
Lewis, J. R. (1982, October). Testing small system customer set-up. In Proceedings of the Human Factors Society Annual Meeting (Vol. 26, No. 8, pp. 718-720). Sage CA: Los Angeles, CA: SAGE Publications.
Lewis, J. R. (2006). Sample sizes for usability tests: mostly math, not magic, interactions, v. 13 n. 6. November+ December.
Mills, C., Bury, K. F., Roberts, T., Tognazzini, B., Wichansky, A., & Reed, P. (1986, April). Usability testing in the real world. In ACM SIGCHI Bulletin (Vol. 17, No. 4, pp. 212-215). ACM.
Molich, R. (2010). A critique of how to specify the participant group size for usability studies: a practitioner’s guide by Macefield. Journal of Usability Studies, 5(3), 124-128.
Nielsen, J. (1994). Guerrilla HCI: Using discount usability engineering to penetrate the intimidation barrier. Cost-justifying usability, 245-272.
Nielsen, J. (2000). Why you only need to test with 5 users.
Racheva, Z., Daneva, M., Herrmann, A., & Wieringa, R. J. (2010, May). A conceptual model and process for client-driven agile requirements prioritization. In 2010 Fourth International Conference on Research Challenges in Information Science (RCIS) (pp. 287-298). IEEE.
Spool, J., & Schroeder, W. (2001, March). Testing web sites: Five users is nowhere near enough. In CHI’01 extended abstracts on Human factors in computing systems (pp. 285-286). ACM.
Tversky, A., & Kahneman, D. (1971). Belief in the law of small numbers. Psychological bulletin, 76(2), 105.
Virzi, R. A. (1992). Refining the test phase of usability evaluation: How many subjects is enough?. Human factors, 34(4), 457-468.
Back to Top